import jax
from jax import numpy as jnp
from typing import Any, Callable, SequenceDeep learning solution method with all-in-one expectation operator
This is a JAX version using FLAX for neural networks and Optax for the optimization.
Similar code can be found for tensorflow and torch
- This companian notebook illustrates a deep learning framework for solving dynamic economic models introduced by Maliar, Maliar and Winant (2018, 2019) in the paper “Will Artificial Intelligence Replace Computational Economists Any Time Soon?”.
- In the paper, we offer a unified approach for casting three fundamental objects of economic dynamics – lifetime reward, Bellman equation and Euler equation – into objective functions of the deep learning framework.
- In the notebook, we illustrate only one of the three approaches – the Euler residual minimization.
- We solve a cannonical consumption-saving problem with occasionally binding borrowing constraint and four exogenous stochastic shocks.
- We parameterize the agent’s decision function with a multilayer neural network, and we perform training using stochastic optimization, namely, in each iteration, we train the model on just one or few grid points that are randomly drawn from the state space (instead of using a conventional fixed grid with a potentially large number of grid points).
- Our objective function – the sum of squared residuals in the Euler equation – has two types of expectation operators, one is with respect to current state variables (which arises because grid points that are randomly drawn from the state space), and the other is with respect to future state variables (which arises because next-period shocks are randomly drawn from the given distributions).
- We construct all-in-one expectation method that merges the two expectation operators into one. Namely, we use two independent random draws for evaluating two terms of a squared residual – this method eliminates the correlation between the terms and pulls the expectation operator out of the square. Our all-in-one expectation operator allows for efficient parallel calculations and reduces greately the cost of training deep neural networks.
JAX and libraries
JAX
This notebook uses several libraries. A missing library x can be installed using pip install x
import numpy as np
# from math import sqrt
from matplotlib import pyplot as plt
from tqdm import tqdm as tqdm # tqdm is a nice library to visualize ongoing loops
import datetime
# followint lines are used for indicative typing
from typing import Tuple
class Vector: passThe model
We consider the following consumption-saving problem:
\[\begin{gather*} \underset{\left\{ c_{t},w_{t+1}\right\}_{t=0}^{\infty }}{\max }E_{0}\left[ \sum_{t=0}^{\infty }\exp (\delta_{t})\beta ^{t}u\left( {c_{t}}\right)\right] \\ \text{s.t. }w_{t+1}=\left( w_{t}-c_{t}\right) \overline{r}\exp (r_{t})+\exp (y_{t}), \\ c_{t}\leq w_{t}, \end{gather*}\]
where \(c_{t}\) is consumption; \(w_{t}\) is the beginning-of-period cash-on-hand; \(\beta \in \left[ 0,1\right)\) is a subjective discount factor; \(\overline{r}\in \left( 0,\frac{1}{\beta }\right)\) is a (gross) constant interest rate; and initial condition \(\left( z,w\right)\) is given. There is an occasionally binding inequality constraint: consumption \(c_{t}\) cannot exceed cash-on-hand \(w_{t}\). There are four different exogenous state variables, namely, shocks to the interest rate (\(r_{t}\)), discount factor (\(\delta_t\)), transitory component of income \(q_{t}\) and permanent component of income \(p_{t}\). The total income is \(y_{t}=p_{t}q_{t}\). All exogenous variables follows AR(1) processes:
\[\begin{gather*} y_{t+1} &=&\rho_{y}y_{t}+\sigma_{y}\epsilon_{t}, \\ p_{t+1} &=&\rho_{p}p_{t}+\sigma_{p}\epsilon_{t}, \\ r_{t+1} &=&\rho_{r}r_{t}+\sigma_{r}\epsilon_{t}, \\ \delta_{t+1} &=&\rho_{\delta }\delta_{t}+\sigma_{\delta }\epsilon_{t}, \end{gather*}\]
where \(\epsilon_t \sim \mathcal{N}\left( 0,1\right)\). We assume the Cobb-Douglas utility function \(u\left( {c_{t}}\right) =\frac{1}{1-\gamma }\left( c_{t}^{1-\gamma }-1\right)\). The model’s parameters are specified below.
# Model parameters
β = 0.9
γ = 2.0
# σ = 0.1
# ρ = 0.9
σ_r = 0.001
ρ_r = 0.2
σ_p = 0.0001
ρ_p = 0.999
σ_q = 0.001
ρ_q = 0.9
σ_δ = 0.001
ρ_δ = 0.2
rbar = 1.04Stochastic solution domain
We solve the model on a random grid which is drawn from the following domain:
- for AR1 processes, we take the ergodic distribution (recall that for an AR(1) process \(z\) with autocorrelation \(\rho\) and conditional standard deviation \(\sigma\), the ergodic distribution is normal with zero mean and standard deviation \(\sigma_z= \frac{\sigma}{\sqrt{1-\rho^2}}\).
- for available income we choose a uniform distribution between two finite bounds: \(w\in[w_{\min}, w_{\max}]\).
# Standard deviations for ergodic distributions of exogenous state variables
σ_e_r = σ_r/(1-ρ_r**2)**0.5
σ_e_p = σ_p/(1-ρ_p**2)**0.5
σ_e_q = σ_q/(1-ρ_q**2)**0.5
σ_e_δ = σ_δ/(1-ρ_δ**2)**0.5
# bounds for available income
wmin = 0.1
wmax = 4.0Kuhn-Tucker conditions
In the recursive form, the solution can be characterized by the Kuhn-Tucker (KT) conditions \[\begin{equation*} a\geq 0,\quad b\geq 0\quad and\quad ab=0, \end{equation*}\] where \(a\) is the share of income that goes to savings and \(b\) is the Lagrange multiplier \[\begin{gather*} a &\equiv &w-c , \\ b &\equiv &u^{\prime }(c)-\beta \overline{r}E_{\epsilon }\left[ \left. u^{\prime }\left( c^{\prime }\right) \exp \left( \delta ^{\prime }-\delta +r^{\prime }\right) \right\vert \epsilon \right] . \end{gather*}\] (In the absence of borrowing constraint \(b=0\), the KT conditions lead to the familiar Euler equation).
Inequality constraints are not directly compatible with the deep learning framework developed in the paper, so we reformulate the KT conditions as a set of equations that hold with equality. We use a smooth representation of the KT conditions, called the Fischer-Burmeister (FB) function, which is differentiable \[\begin{equation*} FB\left( a,b\right) =a+b-\sqrt{a^{2}+b^{2}}=0. \end{equation*}\] The restriction \(FB\left( a,b\right) =0\) is also equivalent to the KT conditions.
For numerical treatment, we rewrite the FB function in the following unit-free form \[\begin{equation*} FB\left( 1-\zeta ,1-h\right) =(1-\zeta)+(1-h)-\sqrt{(1-\zeta)^{2}+(1-h)^{2}}=0, \end{equation*}\] where \(\zeta\) and \(h\) are respectively the consumption share and normalized Lagrange multiplier \[\begin{gather*} \zeta &\equiv &\frac{c}{w}, \\ h &\equiv &\beta \overline{r}E_{\epsilon }\left[ \left. \frac{u^{\prime }\left( c^{\prime }\right) }{u^{\prime }(c)}\exp \left( \delta ^{\prime }-\delta +r^{\prime }\right) \right\vert \epsilon \right] . \end{gather*}\] In particular, \(\zeta\) belongs to the interval \(\left[0,1\right]\) which is a convenient domain for defining neural network. In turn, \(h\) is normalized to be around one: we will parameterize it with neural network in the way that ensures that it is nonnegative.
# here are the Fisher Burmeister functions with JAX
min_FB = lambda a,b: a+b-jnp.sqrt(a**2+b**2)
max_FB = lambda a,b: -min_FB(-a,-b)Parameterizing decision functions with neural network
There are many different decision functions that we can approximate for characterizing the solution, including consumption, next-period income, etc. We chose to approximate the two functions that we defined earlier: the share of consumption, \(\zeta \equiv \frac{c}{w}\), and the normalized Lagrange multiplier \(h\). Since the model is stationary, we look for a decision rule \[\begin{equation*} \left( \begin{matrix} \zeta \\ h% \end{matrix}% \right) =\varphi (s;\theta ), \end{equation*}\] where \(s=(r, \delta, q, p, w)\) is the 5-dimensional state space, and \(\varphi\) is a function to be determined.
A common approach in computational economics is to approximate an unknown function \(\varphi\) using some flexible function family \(\varphi(...;\theta)\) parameterized by a vector of coefficients \(\theta\), e.g., a polynomial family. Neural networks are just a special family of approximating functions. A distinctive feature of neural networks is that they have a nonlinear dependence of the approximation function on the coefficients \(\theta\). TensorFlow contains a submodule keras, which makes it easy to build such a network. Below, we build the multilayer perceptrion: a 2 hidden layers 32x32x32x2 network with relu activation functions and linear outputs.
import flax
from flax import nnx # old API
from flax import linen as nn # new stateless APIclass MLP(nn.Module):
def __init__(self):
self.linear1 = nn.Dense(32)
self.linear2 = nn.Dense(32)
self.linear3 = nn.Dense(32)
self.linear4 = nn.Dense(2)
def __call__(self, x: jax.Array):
x = nnx.relu(self.linear1(x))
x = nnx.relu(self.linear2(x))
x = nnx.relu(self.linear3(x))
x = self.linear4(x)
return x
class ExplicitMLP(nn.Module):
features: Sequence[int]
def setup(self):
# we automatically know what to do with lists, dicts of submodules
self.layers = [nn.Dense(feat) for feat in self.features]
# for single submodules, we would just write:
# self.layer1 = nn.Dense(feat1)
def __call__(self, inputs):
x = inputs
for i, lyr in enumerate(self.layers):
x = lyr(x)
if i != len(self.layers) - 1:
x = nn.relu(x)
return x# this creates a 3 layer perceptron with 32 neurons on each.
model = ExplicitMLP(features=[32,32,32,2])# the following code initializes the neural network with random values
key1, key2 = jax.random.split(jax.random.PRNGKey(0), 2)
x = jax.random.uniform(key1, (5,))
theta_0 = model.init(key2, x)
# all the trainable parameters of the NN are stored in theta_0
# it is a "pytree", that we will be able to use to compute gradients# pretty print requres the library `treescope` to be installed
nnx.display(model)Next, we create the decision rule which takes as input 5 vectors of the same size \(n\) for the states \(r\), \(\delta\), \(q\), \(p\), \(w\) and returns two vectors of size \(n\) for \(\zeta\) and \(h\), respectively. We use different nonlinear transformation for the two decision functions:
\[\begin{equation*} \varphi(s;\theta)=\left(\begin{matrix}\frac{1}{1+e^{-nn(s;\theta)}}\\ \exp(nn(s;\theta))\end{matrix}\right) \end{equation*}\]
where nn denotes neural network; the first and second elements in the vector function \(\varphi\) are used to get \(\zeta\in[0,1]\) and \(h>0\), respectively.
def dr(theta, r: Vector, p: Vector, q: Vector, δ: Vector, w: Vector)-> Tuple[Vector, Vector]:
# we normalize exogenous state variables by their 2 standard deviations
# so that they are typically between -1 and 1
r = r/σ_e_r/2
δ = δ/σ_e_δ/2
q = q/σ_e_q/2
p = p/σ_e_p/2
# we normalze income to be between -1 and 1
w = (w-wmin)/(wmax-wmin)*2.0-1.0
# we prepare input to the perceptron
# s = tf.concat([_e[:,None] for _e in [r,p,q,δ,w]], axis=1) # equivalent to np.column_stack
s = jnp.column_stack([r,p,q,δ,w])
x = model.apply(theta, s) # n x 2 matrix
# consumption share is always in [0,1]
ζ = jax.nn.sigmoid( x[:,0] )
# expectation of marginal consumption is always positive
h = jnp.exp( x[:,1] )
return (ζ, h)Finally, as an illustration, we plot the initial guess of decision rules against \(w\). Note that the coefficients of the perceptron are initialized with random values, so that each run will provide a different plot. Here, we are using TensorFlow in an eager mode, i.e., calculations are returned immediately, so that the library essentially behaves in the same way as numpy, and is in fact mostly compatible with it.
wvec = jnp.linspace(wmin, wmax, 100)
# r,p,q,δ are zero-mean
ζvec, hvec = dr(theta_0, wvec*0, wvec*0, wvec*0, wvec*0, wvec)plt.plot(wvec, wvec, linestyle='--', color='black')
plt.plot(wvec, wvec*ζvec)
plt.xlabel("$w_t$")
plt.ylabel("$c_t$")
plt.title("Initial Guess")
plt.grid()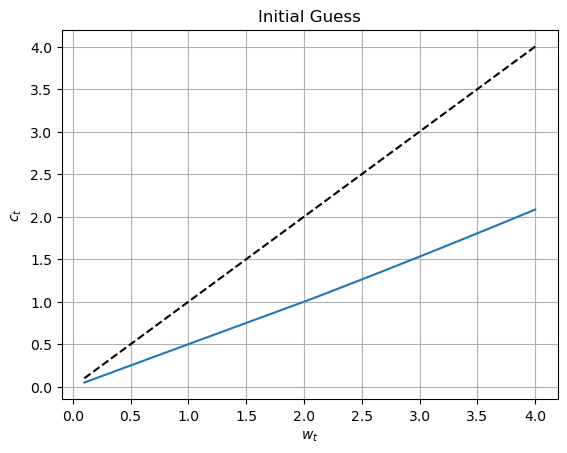
Residuals in the model’s equations
To identify the unknown decision functions for \(\zeta\) and \(h\), we use two modelp’s equations, namely, the definition of normalized Lagrange multiplier and the FB function representing the KT conditions, respectively: \[\begin{gather*} h=\beta \overline{r}E_{\epsilon }\left[ \left. \frac{u^{\prime }\left( c^{\prime }\right) }{u^{\prime }(c)}\exp \left( \delta ^{\prime }-\delta +r^{\prime }\right) \right\vert \epsilon \right] , \\ FB\left( 1-\zeta ,1-h\right) =0 \end{gather*}\] where \(\epsilon=(\epsilon_r,\epsilon_\delta,\epsilon_q,\epsilon_p)\).
We do not need to include the definition \(\zeta = \frac{c}{w}\) because we will impose it to hold exactly in the solution by setting \(c=w\zeta\) and \(c^{\prime}=w^{\prime}\zeta ^{\prime}\).
We next construct the residuals in the above two equations which we will minimize. For given vectors of next-period shocks \(\epsilon=(\epsilon_r,\epsilon_\delta,\epsilon_q,\epsilon_p)\), state \(s=(r,\delta ,q,p,w)\) and next-period shocks, we define: \[\begin{equation*} \begin{matrix} R_1(s,\epsilon)=\beta \overline{r}\left[ \left. \frac{u^{\prime }\left( c^{\prime }\right) }{u^{\prime }(c)}\exp \left( \delta ^{\prime }-\delta +r^{\prime }\right) \right\vert \epsilon \right] -h, \\ R_2(s)=FB\left( 1-\zeta ,1-h\right), \end{matrix} \end{equation*}\] where the transition equation is \(w^{\prime }=\left( w-c\right) \overline{r% }\exp (r)+\exp (y)\).
def Residuals(theta, e_r: Vector, e_p: Vector, e_q: Vector, e_δ: Vector, r: Vector, p: Vector, q: Vector, δ: Vector, w: Vector):
# all inputs are expected to have the same size n
n = r.shape[0]
# arguments correspond to the values of the states today
ζ, h = dr(theta, r, p, q, δ, w)
c = ζ*w
# transitions of the exogenous processes
rnext = r*ρ_r + e_r
pnext = p*ρ_p + e_p
qnext = q*ρ_q + e_q
δnext = δ*ρ_δ + e_δ
# (epsilon = (rnext, δnext, pnext, qnext))
# transition of endogenous states (next denotes variables at t+1)
wnext = jnp.exp(pnext)*jnp.exp(qnext) + (w-c)*rbar*jnp.exp(rnext)
ζnext, hnext = dr(theta, rnext, pnext, qnext, δnext, wnext)
cnext = ζnext*wnext
R1 = β*jnp.exp(δnext-δ)*(cnext/c)**(-γ)*rbar*jnp.exp(rnext) - h
R2 = min_FB(1-h,1-ζ)
return (R1, R2)The expected squared sum of residuals
We construct the objective function for minimization as the squared sum of two residuals in the two model’s equations on a given 5-dimensional domain \(s=(r,\delta ,q,p,w)\): \[\begin{equation*}
\Xi (\theta )=E_{s}\left[ \left( E_{\epsilon }\left[ \left.R_1(s,\epsilon)\right\vert
\epsilon \right] \right) ^{2}+v\left( R_2(s)\right) ^{2}\right] ,
\end{equation*}\] where \(v\) is the exogenous relative weights of the two residuals in the objective function. We placed the first residual \(R_1(s,\epsilon)\) under the expectation operator \(E_{\epsilon }\) across next-period shocks $=( {r},{},{q},{p}) $ as is required by the definition of \(h\); the second residual \(R_2(s)\) does not include random variables
and requires no expectation operator. The value of the objective function \(\Xi (\theta )\) depends on the coefficients $$ because these coefficients determine the choices via
\[\begin{equation*}
\left(
\begin{matrix}
\zeta \\
h%
\end{matrix}%
\right) =\varphi (s;\theta ).
\end{equation*}\] A shortcoming of the constructed objective function is that it requires a potentially costly evaluation of two nested expectation operators: for each random grid point \(s=(r,\delta ,q,p,w)\), we need to construct a separate approximation of the expectation function $E_{}$ by considering a potentially large number of next period shocks $=( {r}, {},{q},{p}) \(. In particular, if there are\)n$ grid points and \(J\) next-period shocks, we have \(n\times J\) function evaluations.
All-in-one expectation function
We now introduce a technique which we call an all-in-one expectation operator that makes it possible to merge the two expectation operators into a single one. This technique relies on a simple result from probability theory that says that for two random variables \(a\) and \(b\), which are independent and follow the same distribution, we have \(E[a]^{2}=E[a]E[b]=E[ab]\).
Therefore, we replace \(\left( E_{\epsilon }\left[ \left. R_1(s,\epsilon)\right\vert \epsilon \right] \right) ^{2}\) by the product of two residuals constructed by using two uncorrelated random draws \(\epsilon _{1}\) and \(\epsilon _{2}\), and as a result, we can pull the expectation out of squares \[\begin{equation*} E_{\epsilon _{1}}\left[ \left. R_1(s,\epsilon_1)\right\vert \epsilon _{1}\right] E_{\epsilon _{2}}\left[ \left. R_1(s,\epsilon_2)\right\vert \epsilon _{2}\right] =E_{\epsilon _{1},\epsilon _{2}}\left[ \left( \left. R_1(s,\epsilon_1)\right\vert \epsilon _{1}\right) \left( \left. R_1(s,\epsilon_2)\right\vert \epsilon _{2}\right) \right]. \end{equation*}\] With that result, we can re-write the objective function as just one expectation operator: \[\begin{equation*} \Xi (\theta )=E_{s,\epsilon _{1}\epsilon _{2}}\left[ \underset{\xi (\omega ;\theta )}{\underbrace{\left[ \left( \left. R_{1}\left( s,\epsilon _{1}\right) \right\vert \epsilon _{1}\right) \left( \left. R_{1}\left( s,\epsilon _{2}\right) \right\vert \epsilon _{2}\right) \right] +v\left( R_{2}\left( s\right) \right) ^{2}}}\right] \equiv E_{\omega }\left[ \xi (\omega ;\theta )\right], \end{equation*}\] where \(\omega =(s,\epsilon _{1},\epsilon _{2})\). Therefore, we wrote the objective function of the deep learning method as a single expectation operator $E_{}$ of a function \(% \xi (\omega ;\theta )\) that depends on a vector-valued random variable $% $. We approximate \(\Xi (\theta )\) by using Monte Carlo simulation: \[\begin{equation*} \Xi (\theta )\approx \Xi ^{n}(\theta )=\frac{1}{n}\sum_{i=1}^{n}\xi (\omega _{i};\theta ), \end{equation*}\] i.e., we draw \(n\) random draws of \(\omega =(s,\epsilon _{1},\epsilon _{2})\) and compute the average of the objective function.
def Ξ(n, theta, key): # objective function for DL training
keys = jax.random.split(key, 13)
# randomly drawing current states
r = jax.random.normal(keys[0], shape=(n,))*σ_e_r
p = jax.random.normal(keys[1], shape=(n,))*σ_e_p
q = jax.random.normal(keys[2], shape=(n,))*σ_e_q
δ = jax.random.normal(keys[3], shape=(n,))*σ_e_δ
w = jax.random.uniform(keys[4], shape=(n,), minval=wmin, maxval=wmax)
# randomly drawing 1st realization for shocks
e1_r = jax.random.normal(keys[5], shape=(n,))*σ_r
e1_p = jax.random.normal(keys[6], shape=(n,))*σ_p
e1_q = jax.random.normal(keys[7], shape=(n,))*σ_q
e1_δ = jax.random.normal(keys[8], shape=(n,))*σ_δ
# randomly drawing 2nd realization for shocks
e2_r = jax.random.normal(keys[9], shape=(n,))*σ_r
e2_p = jax.random.normal(keys[10], shape=(n,))*σ_p
e2_q = jax.random.normal(keys[11], shape=(n,))*σ_q
e2_δ = jax.random.normal(keys[12], shape=(n,))*σ_δ
# residuals for n random grid points under 2 realizations of shocks
R1_e1, R2_e1 = Residuals(theta, e1_r, e1_p, e1_q, e1_δ, r, p, q, δ, w)
R1_e2, R2_e2 = Residuals(theta, e2_r, e2_p, e2_q, e2_δ, r, p, q, δ, w)
# construct all-in-one expectation operator
R_squared = R1_e1*R1_e2 + R2_e1*R2_e2
# compute average across n random draws
return jnp.mean(R_squared)So far, we have been using JAX in the eager execution mode as if it was numpy: result of each operation is computed immediately.
n = 128
key = jax.random.key(13)
v = Ξ(n, theta_0, key)
vArray(0.32632732, dtype=float32)Note that the intermediate results are still stored as special JAX objects (tensors) and they can be converted to a regular value easily.
float(v)0.3263273239135742Model training
We are now ready to perform minimization of the objective \(\Xi_n\), hence to solve (or to train) the model using stochastic optimization - the stochastic gradient descent method, and in particular, its version called Adam.
Now it is time to choose an optimizer. In TensorFlow, the optimizer object is in charge of performing the optimization steps, given the computed gradient. For the stochastic gradient descent, the updating rule would be: \[\theta \leftarrow \theta(1-\lambda) - \lambda\nabla_{\theta} \Xi_n(\theta)\] where \(\lambda\) is a learning rate. For Adam, the learning rate evolves over time and can be specific to each coefficient.
import optaxoptimizer = optax.adam(1e-3)
opt_state = optimizer.init(theta_0)@nnx.jit # Automatic state management
def train_step(theta, opt_state, key):
n = 128
def loss_fn(theta):
return Ξ(n, theta, key)
loss, grads = nnx.value_and_grad(loss_fn)(theta)
updates, opt_state = optimizer.update(grads, opt_state)
theta = optax.apply_updates(theta, updates)
return theta, opt_state, losskey = jax.random.key(0)
train_step(theta_0, opt_state, key)({'params': {'layers_0': {'bias': Array([-0.00099999, 0.00099999, -0.00099999, -0.00099999, -0.00099999,
-0.00099999, 0.00099998, -0.00099999, -0.00099999, -0.00099999,
0.00099999, -0.00099999, -0.00099984, 0.00099999, -0.00099999,
-0.00099998, 0.00099999, -0.00099999, 0.00099999, 0.00099999,
0.00099999, 0.00099999, -0.00099999, 0.00099999, 0.00099999,
0.00099999, 0.00099999, -0.00099999, -0.00099999, -0.00099999,
0.00099999, -0.00099999], dtype=float32),
'kernel': Array([[ 2.90576994e-01, 6.10086501e-01, 4.28756237e-01,
-6.69481903e-02, 6.00531399e-01, -7.30138049e-02,
3.16190541e-01, -5.10465145e-01, -3.16770405e-01,
-8.65175277e-02, 6.08206876e-02, 4.35658604e-01,
6.39521599e-01, 3.28503340e-01, -6.03019536e-01,
-4.87558842e-01, 3.27692926e-01, -1.23124393e-02,
-5.09673655e-01, 2.97018766e-01, 8.52716088e-01,
5.77055328e-02, 1.13907695e-01, 3.45427603e-01,
1.42134741e-01, 6.63150027e-02, -4.24780965e-01,
2.87633657e-01, 3.57178450e-02, -2.30897903e-01,
2.34282553e-01, -6.76139295e-01],
[ 6.84976161e-01, 2.80706763e-01, 2.75065601e-01,
7.58876741e-01, 3.25741947e-01, 5.62200487e-01,
-6.11043572e-01, -4.06330407e-01, -2.17019260e-01,
-2.87477553e-01, 3.14743549e-01, 3.64510477e-01,
-2.45555520e-01, -8.65781844e-01, 5.64136386e-01,
3.47741902e-01, 3.65129709e-01, -5.10530844e-02,
3.61090273e-01, 3.68901372e-01, 8.07801709e-02,
-1.71740338e-01, 1.92454919e-01, 6.00643098e-01,
9.06348228e-01, -5.07585049e-01, 3.98297489e-01,
5.67231953e-01, -2.12654546e-01, -3.02104354e-01,
-4.91601378e-01, 2.59259045e-01],
[-7.29679987e-02, -6.03428967e-02, -7.13421583e-01,
6.31961450e-02, -4.33356732e-01, 2.13028073e-01,
-2.37776294e-01, 1.90861136e-01, 1.89057350e-01,
1.45647347e-01, 2.09887996e-01, -5.14245212e-01,
1.68102026e-01, -3.63973260e-01, -9.45541978e-01,
2.85150886e-01, -5.58416307e-01, 5.52608013e-01,
-9.17331278e-01, 2.00041890e-01, -8.91367197e-01,
9.32728723e-02, 1.70245662e-01, 7.86572993e-01,
9.49022267e-03, -7.22944260e-01, -3.39623481e-01,
3.47313643e-01, -8.22086930e-01, 9.17533457e-01,
7.73751438e-01, -9.76893067e-01],
[-6.76029742e-01, 2.18309313e-01, -2.10780114e-01,
-1.93245322e-01, -7.26927578e-01, 1.16271481e-01,
-8.94776106e-01, -8.66588131e-02, -7.42582202e-01,
3.74925017e-01, 4.08008397e-01, 6.59836829e-01,
3.55684847e-01, 5.77436876e-04, -1.15606077e-01,
-3.29018146e-01, 9.37580168e-01, -3.51309687e-01,
-6.93765223e-01, 1.44256074e-02, 3.86868238e-01,
1.40711576e-01, 3.38916570e-01, 8.79223228e-01,
6.65049374e-01, -5.01968622e-01, 3.28865111e-01,
1.78459436e-01, 5.09950519e-01, 1.65947109e-01,
2.92391419e-01, -2.44030878e-01],
[-9.68230963e-01, 5.36674522e-02, 9.87019122e-01,
1.68127075e-01, 1.37939543e-01, -4.18502063e-01,
-1.87593296e-01, 1.63010642e-01, 9.11239088e-01,
5.49989194e-03, 5.18459380e-02, 1.88091546e-01,
-2.45355919e-01, 4.55460101e-01, 5.99510789e-01,
1.32816464e-01, 1.54927792e-02, -1.01026252e-01,
-5.66997886e-01, -1.33938938e-01, -6.94246829e-01,
3.93039316e-01, 4.63874102e-01, 9.67177689e-01,
2.69299001e-01, -7.11216509e-01, 4.26159799e-01,
2.96553403e-01, 2.37350658e-01, 4.29906458e-01,
1.98319793e-01, 1.69716746e-01]], dtype=float32)},
'layers_1': {'bias': Array([-0.00099999, 0.00099999, 0.00099999, -0.00099999, -0.00099999,
-0.00099999, -0.00099999, -0.00099999, 0.00099999, 0.00099998,
0.00099999, -0.00099999, -0.00099999, -0.00099857, -0.00099999,
0.00099999, 0.00099999, 0.00099999, 0.00099999, -0.00099999,
0.00099999, -0.00099999, 0.00099999, -0.00099999, -0.00099999,
-0.00099999, -0.00099999, 0.00099999, 0.00099998, -0.00099999,
-0.00099999, -0.00099999], dtype=float32),
'kernel': Array([[ 0.08028451, -0.12694463, -0.16517161, ..., -0.09011469,
0.11818608, 0.27721205],
[ 0.27888992, 0.17136027, -0.08418229, ..., -0.00655951,
0.21156475, -0.09107073],
[ 0.05083922, 0.24567221, -0.1615431 , ..., -0.09922998,
0.31926593, -0.21564198],
...,
[-0.29852524, 0.2161529 , -0.07271834, ..., -0.19646876,
-0.36503586, 0.01950573],
[-0.3862267 , 0.17947868, 0.25355363, ..., -0.19096345,
0.26527345, -0.2222944 ],
[ 0.04879192, -0.23138039, 0.14187574, ..., 0.23447008,
-0.07781439, -0.01152448]], dtype=float32)},
'layers_2': {'bias': Array([ 0.00099999, -0.00099998, -0.00099999, -0.00099992, 0.00099999,
-0.00099999, 0.00099999, -0.00099999, 0.00099999, -0.00099999,
0.00099999, 0.00099998, 0.00099999, 0.00099999, 0.00099999,
0.00099999, -0.00099999, -0.00099999, -0.00099999, 0.00099999,
-0.00099999, -0.00099996, 0.00099999, -0.00099999, 0.00099999,
-0.00099999, -0.00099999, -0.00099999, -0.00099999, 0.00099999,
-0.00099999, 0.00099999], dtype=float32),
'kernel': Array([[ 0.10576341, -0.34913623, 0.29568854, ..., -0.04602984,
0.0526979 , 0.2529758 ],
[-0.09528456, -0.00379137, 0.1706552 , ..., 0.08860844,
-0.29843187, 0.35976106],
[-0.34404194, 0.16272418, 0.27824655, ..., -0.07253396,
0.24329141, 0.21488856],
...,
[ 0.08721483, 0.064231 , 0.05546777, ..., 0.3064761 ,
-0.09369519, -0.062145 ],
[ 0.24008322, -0.20132665, 0.01569657, ..., -0.34995735,
0.2803042 , -0.36960876],
[-0.0707825 , 0.17653075, -0.20318094, ..., -0.02054866,
-0.09215975, -0.09089494]], dtype=float32)},
'layers_3': {'bias': Array([-0.00099999, 0.00099999], dtype=float32),
'kernel': Array([[ 0.03813289, 0.3262104 ],
[ 0.01450743, -0.09098117],
[-0.09283216, -0.19298944],
[ 0.05055879, 0.0760477 ],
[-0.02906282, -0.03922855],
[ 0.10332084, -0.30678308],
[ 0.09477834, -0.03677274],
[ 0.09960643, 0.03413736],
[-0.12843114, 0.09858599],
[ 0.1468802 , -0.19938262],
[ 0.06454647, -0.1418309 ],
[ 0.04126251, 0.15201563],
[-0.00320409, 0.21408913],
[-0.00145276, 0.19818756],
[-0.14545786, 0.11385514],
[-0.1748309 , -0.12620309],
[ 0.09987191, 0.32951805],
[ 0.18455799, -0.1477907 ],
[-0.09346157, 0.22150539],
[-0.11167234, 0.1914164 ],
[ 0.21227238, -0.07227054],
[-0.15438405, -0.04312037],
[-0.16902089, -0.09351698],
[ 0.02293933, -0.24821205],
[-0.24305552, -0.17213082],
[ 0.11003602, -0.13708307],
[ 0.00808613, 0.1649792 ],
[ 0.09057406, 0.24668163],
[ 0.2624336 , 0.03973389],
[-0.02355043, 0.11765958],
[-0.14609647, -0.02810595],
[-0.37713435, 0.3332066 ]], dtype=float32)}}},
(ScaleByAdamState(count=Array(1, dtype=int32), mu={'params': {'layers_0': {'bias': Array([ 1.1610985e-03, -1.5785731e-04, 2.9649958e-03, 2.9601741e-03,
2.8981618e-03, 1.0022663e-03, -8.4839645e-05, 2.3535339e-04,
3.3552491e-03, 1.8098004e-03, -1.8397158e-04, 4.7317237e-04,
6.3268235e-06, -5.6343043e-04, 9.8007196e-04, 8.0950929e-05,
-1.7672547e-03, 1.2257324e-03, -1.8255651e-03, -1.2666672e-04,
-2.8531157e-04, -1.9631609e-03, 3.8738374e-03, -2.3737669e-03,
-1.2869043e-04, -1.0109490e-03, -1.1227505e-03, 1.6362248e-04,
3.6036670e-03, 6.9978397e-04, -1.7915590e-03, 1.0418568e-03], dtype=float32), 'kernel': Array([[-7.22040058e-05, 1.53594647e-05, 4.88708145e-04,
3.81832011e-04, 2.44939147e-04, 7.24025522e-05,
1.91746021e-05, -3.65896180e-04, 4.68772283e-04,
-2.86479073e-04, -6.03974797e-04, -1.05120962e-04,
5.23376744e-04, -5.21233778e-05, -2.85338210e-05,
-1.54001929e-04, -4.31772409e-04, 1.92119958e-04,
4.48981737e-04, 6.65668413e-05, -3.48771602e-04,
-2.65865034e-04, -9.65117011e-04, 2.05182936e-04,
-3.70165071e-04, 5.66115545e-04, -1.90343679e-04,
-1.66096026e-04, 1.25824439e-03, -3.88119544e-04,
1.23154517e-04, -2.31026916e-05],
[ 4.89163038e-04, 4.30099026e-04, -3.59542115e-04,
8.37585831e-04, -1.15018839e-03, 4.47002851e-04,
-3.33322998e-04, 4.87879806e-05, -1.26437040e-03,
-8.74701247e-04, -4.39809461e-04, -3.96147283e-04,
1.05112194e-05, -1.92536376e-04, 6.39478618e-04,
-1.40724645e-03, -3.34347133e-05, -5.75745478e-04,
-4.65678604e-04, -1.30364482e-04, -6.80483819e-04,
2.56998406e-04, -1.13183330e-03, -1.65190315e-04,
5.56039799e-04, -5.53953112e-04, -4.17023519e-04,
7.57486676e-04, -1.81320662e-04, -5.73505880e-04,
1.44192786e-03, 4.81695781e-04],
[-1.84322547e-04, -5.15859982e-04, -3.12794691e-05,
1.13297392e-04, -1.14132185e-03, -5.04481257e-04,
4.48633742e-04, 2.50354147e-04, -3.31092830e-04,
7.02189049e-04, 1.35901838e-03, 1.13535920e-04,
-2.36838925e-04, 5.98770566e-04, -2.06489800e-04,
4.85669647e-04, -6.40846964e-04, -5.36502910e-07,
-2.46419921e-04, -2.87929899e-04, 2.02413416e-04,
-1.11356378e-03, 1.30795396e-03, -9.17787838e-04,
1.81943411e-04, 4.64540208e-05, 2.59571098e-04,
-1.09689114e-04, -5.12986910e-04, 3.27766611e-04,
5.07674231e-05, -4.51540167e-04],
[-3.38606886e-04, -3.74235271e-04, -4.08214139e-04,
1.98496462e-04, -3.65170126e-04, -3.60432787e-05,
5.31398167e-04, -2.00321927e-04, -5.22572547e-04,
-2.60606321e-04, 3.95079369e-05, 3.82340717e-04,
3.65417509e-04, -4.23041085e-04, 3.13076489e-05,
3.85260035e-04, -6.96144940e-04, -7.64470024e-04,
3.17804588e-05, 1.94342676e-04, -5.21539594e-04,
-6.39488630e-04, 2.79110518e-05, -1.96026507e-04,
-1.47102997e-04, 8.18498447e-05, -2.09077290e-04,
-3.35045537e-04, 2.58326560e-04, -5.16871165e-04,
6.66958396e-04, 2.24193049e-04],
[-4.55799105e-04, 6.42167171e-04, 2.36004754e-03,
1.87339063e-03, 3.88074457e-03, -1.70167710e-03,
-9.45172564e-04, 1.92673950e-04, 2.81658070e-03,
1.60764612e-03, -1.53058820e-04, 4.01552621e-04,
1.49758591e-03, -2.64901348e-04, -9.67555170e-05,
3.35702789e-03, -9.82270925e-04, -4.29103122e-04,
2.42639706e-03, -6.55521522e-04, -9.43374995e-04,
-1.63675961e-03, 3.65826651e-03, -9.61459649e-04,
-8.60977627e-04, 8.98521044e-04, -1.24521830e-04,
-1.36669993e-03, 3.74836219e-03, 4.47296450e-04,
-1.75623130e-03, 3.16293852e-04]], dtype=float32)}, 'layers_1': {'bias': Array([ 1.0255214e-03, -2.0362840e-03, -4.6704831e-03, 4.4729817e-03,
3.2943015e-03, 2.6577737e-03, 2.3363237e-03, 6.7542531e-03,
-5.9329282e-04, -7.7578079e-05, -1.5448554e-03, 9.1128610e-04,
6.4605579e-04, 7.0342213e-07, 7.5439591e-04, -2.8273363e-03,
-2.1360037e-03, -2.1754436e-03, -6.2120723e-04, 2.5825717e-03,
-2.8127461e-04, 7.0564332e-03, -5.4446945e-04, 2.5121489e-04,
3.1463255e-04, 3.0527969e-03, 9.9508220e-04, -5.3122948e-04,
-7.9325378e-05, 6.5192883e-04, 5.7174778e-03, 2.3097948e-04], dtype=float32), 'kernel': Array([[ 1.0503993e-03, 3.9738232e-05, 2.8346429e-04, ...,
8.5744448e-04, 2.8173157e-04, -1.5256075e-04],
[ 2.4183821e-04, -2.4427386e-04, -5.0296017e-04, ...,
2.1326010e-05, 1.1824876e-03, 2.9672485e-05],
[ 4.4852535e-05, -4.9904658e-04, -2.8696582e-03, ...,
-1.1081108e-04, 5.4301843e-03, 1.6569405e-05],
...,
[ 2.7600136e-05, -2.1624111e-03, -4.6251896e-03, ...,
-1.0869467e-04, 2.0260345e-03, 1.5028972e-04],
[ 9.7452021e-06, -1.8290546e-03, -3.3254796e-03, ...,
-5.5117353e-06, 1.5754321e-03, 1.7556715e-04],
[ 4.3369923e-04, 3.3957639e-04, -9.9846933e-05, ...,
1.3955538e-04, 1.8552553e-03, -1.1987293e-04]], dtype=float32)}, 'layers_2': {'bias': Array([-1.2515523e-03, 9.4605588e-05, 8.7047758e-04, 1.2853253e-05,
-7.8638457e-04, 9.1755635e-04, -1.8248356e-04, 4.0158913e-03,
-5.0827409e-03, 2.6649197e-03, -4.5236843e-04, -8.4423693e-05,
-9.7720500e-04, -4.0328754e-03, -8.6924451e-04, -4.2095929e-03,
2.6289381e-03, 1.2718819e-02, 3.5727357e-03, -1.3274018e-03,
8.4424550e-03, 3.4554581e-05, -1.8476043e-03, 2.4248667e-03,
-2.6244877e-03, 9.2934016e-03, 2.6777852e-04, 1.8664794e-03,
5.3464342e-03, -2.5525538e-03, 8.3061279e-04, -5.1819882e-03], dtype=float32), 'kernel': Array([[-5.44577051e-06, -1.16713905e-04, -4.60018055e-05, ...,
-2.07722383e-06, -6.18789854e-05, 0.00000000e+00],
[-7.93998261e-05, 8.10572121e-04, 1.16737283e-04, ...,
-1.37552246e-03, -9.94031434e-05, -3.22121009e-03],
[-2.99077074e-05, 1.45133687e-04, 1.73992361e-04, ...,
-3.99418845e-04, 1.41460710e-04, -1.18847191e-03],
...,
[-2.86212617e-06, -7.18753363e-05, 2.16050721e-05, ...,
1.00128946e-05, 2.50659414e-05, 0.00000000e+00],
[-1.23733815e-04, 3.44732165e-04, 6.87081047e-05, ...,
-3.21938569e-04, -3.72476963e-04, -2.26426317e-04],
[ 6.95327108e-05, -7.37207418e-04, -3.55845841e-04, ...,
4.78942791e-04, 2.77428306e-04, -1.90869061e-04]], dtype=float32)}, 'layers_3': {'bias': Array([ 0.03821038, -0.0021883 ], dtype=float32), 'kernel': Array([[-2.6561948e-04, -1.5825863e-04],
[ 1.6285888e-03, 3.1668716e-03],
[ 1.1754618e-02, -7.2308085e-03],
[ 7.0295879e-05, -5.7438105e-05],
[ 2.2995721e-03, 2.2321659e-04],
[ 2.5063131e-03, -7.7126548e-04],
[-4.9139035e-04, 2.3996318e-04],
[ 5.9992881e-03, 2.4026118e-03],
[ 1.5737275e-02, -4.9939486e-03],
[ 7.3223113e-04, 8.2112610e-04],
[ 7.9026948e-05, -1.1065897e-04],
[ 3.5669398e-03, -1.7953629e-03],
[ 4.7534253e-04, -2.5701150e-04],
[ 3.2956884e-03, -2.1264318e-03],
[-1.0909732e-04, -2.9557533e-04],
[ 7.5665565e-04, 1.7545104e-03],
[ 5.7965749e-06, 2.5743348e-04],
[ 1.5159343e-02, -8.6595742e-03],
[ 3.0127642e-04, 4.7625061e-03],
[ 7.8693795e-04, -1.9948711e-04],
[ 9.5352484e-03, -8.2871935e-04],
[-7.4921467e-05, -1.4751834e-05],
[ 2.4629110e-03, -1.4924033e-03],
[ 1.1348184e-02, -2.9163870e-03],
[-9.0055820e-04, 2.7288923e-03],
[ 1.3366594e-02, -7.8389449e-03],
[ 3.1334923e-03, 2.4801695e-03],
[ 5.7053089e-04, 9.5921865e-04],
[ 6.9548823e-03, -9.8553218e-04],
[ 1.2823996e-02, -7.0596025e-03],
[-3.7141773e-04, 5.0441641e-04],
[ 6.0272624e-04, -3.1126576e-04]], dtype=float32)}}}, nu={'params': {'layers_0': {'bias': Array([1.3481497e-07, 2.4918934e-09, 8.7912008e-07, 8.7626307e-07,
8.3993416e-07, 1.0045377e-07, 7.1977657e-10, 5.5391216e-09,
1.1257696e-06, 3.2753778e-07, 3.3845542e-09, 2.2389209e-08,
4.0028697e-12, 3.1745383e-08, 9.6054094e-08, 6.5530537e-10,
3.1231889e-07, 1.5024199e-07, 3.3326882e-07, 1.6044457e-09,
8.1402689e-09, 3.8540011e-07, 1.5006617e-06, 5.6347682e-07,
1.6561229e-09, 1.0220179e-07, 1.2605686e-07, 2.6772318e-09,
1.2986416e-06, 4.8969763e-08, 3.2096838e-07, 1.0854656e-07], dtype=float32), 'kernel': Array([[5.2134186e-10, 2.3591318e-11, 2.3883565e-08, 1.4579569e-08,
5.9995187e-09, 5.2421301e-10, 3.6766538e-11, 1.3388002e-08,
2.1974746e-08, 8.2070262e-09, 3.6478557e-08, 1.1050418e-09,
2.7392323e-08, 2.7168467e-10, 8.1417893e-11, 2.3716595e-09,
1.8642742e-08, 3.6910077e-09, 2.0158460e-08, 4.4311446e-10,
1.2164163e-08, 7.0684218e-09, 9.3145090e-08, 4.2100039e-09,
1.3702218e-08, 3.2048685e-08, 3.6230714e-09, 2.7587890e-09,
1.5831789e-07, 1.5063678e-08, 1.5167034e-09, 5.3373434e-11],
[2.3928049e-08, 1.8498518e-08, 1.2927053e-08, 7.0154996e-08,
1.3229335e-07, 1.9981156e-08, 1.1110421e-08, 2.3802671e-10,
1.5986326e-07, 7.6510226e-08, 1.9343236e-08, 1.5693269e-08,
1.1048574e-11, 3.7070256e-09, 4.0893287e-08, 1.9803427e-07,
1.1178801e-10, 3.3148286e-08, 2.1685658e-08, 1.6994900e-09,
4.6305825e-08, 6.6048176e-09, 1.2810466e-07, 2.7287841e-09,
3.0918024e-08, 3.0686405e-08, 1.7390862e-08, 5.7378603e-08,
3.2877183e-09, 3.2890902e-08, 2.0791559e-07, 2.3203082e-08],
[3.3974801e-09, 2.6611151e-08, 9.7840534e-11, 1.2836300e-09,
1.3026157e-07, 2.5450133e-08, 2.0127224e-08, 6.2677192e-09,
1.0962247e-08, 4.9306948e-08, 1.8469309e-07, 1.2890405e-09,
5.6092673e-09, 3.5852622e-08, 4.2638035e-09, 2.3587500e-08,
4.1068486e-08, 2.8783538e-14, 6.0722782e-09, 8.2903631e-09,
4.0971191e-09, 1.2400244e-07, 1.7107435e-07, 8.4233463e-08,
3.3103404e-09, 2.1579760e-10, 6.7377162e-09, 1.2031701e-09,
2.6315558e-08, 1.0743095e-08, 2.5773314e-10, 2.0388851e-08],
[1.1465462e-08, 1.4005203e-08, 1.6663879e-08, 3.9400847e-09,
1.3334922e-08, 1.2991179e-10, 2.8238398e-08, 4.0128874e-09,
2.7308207e-08, 6.7915655e-09, 1.5608771e-10, 1.4618443e-08,
1.3352995e-08, 1.7896376e-08, 9.8016886e-11, 1.4842530e-08,
4.8461779e-08, 5.8441440e-08, 1.0099976e-10, 3.7769081e-09,
2.7200354e-08, 4.0894570e-08, 7.7902677e-11, 3.8426391e-09,
2.1639293e-09, 6.6993971e-10, 4.3713313e-09, 1.1225552e-08,
6.6732611e-09, 2.6715583e-08, 4.4483347e-08, 5.0262523e-09],
[2.0775284e-08, 4.1237872e-08, 5.5698240e-07, 3.5095923e-07,
1.5060178e-06, 2.8957049e-07, 8.9335124e-08, 3.7123251e-09,
7.9331267e-07, 2.5845259e-07, 2.3427003e-09, 1.6124453e-08,
2.2427635e-07, 7.0172725e-09, 9.3616304e-10, 1.1269638e-06,
9.6485628e-08, 1.8412948e-08, 5.8874031e-07, 4.2970846e-08,
8.8995648e-08, 2.6789820e-07, 1.3382914e-06, 9.2440466e-08,
7.4128252e-08, 8.0734004e-08, 1.5505685e-09, 1.8678686e-07,
1.4050220e-06, 2.0007411e-08, 3.0843484e-07, 1.0004181e-08]], dtype=float32)}, 'layers_1': {'bias': Array([1.0516942e-07, 4.1464523e-07, 2.1813410e-06, 2.0007565e-06,
1.0852422e-06, 7.0637611e-07, 5.4584086e-07, 4.5619936e-06,
3.5199637e-08, 6.0183580e-10, 2.3865783e-07, 8.3044242e-08,
4.1738808e-08, 4.9480270e-14, 5.6911318e-08, 7.9938309e-07,
4.5625117e-07, 4.7325543e-07, 3.8589839e-08, 6.6696771e-07,
7.9115399e-09, 4.9793248e-06, 2.9644697e-08, 6.3108923e-09,
9.8993649e-09, 9.3195683e-07, 9.9018870e-08, 2.8220477e-08,
6.2925154e-10, 4.2501121e-08, 3.2689552e-06, 5.3351523e-09], dtype=float32), 'kernel': Array([[1.10333865e-07, 1.57912697e-10, 8.03520184e-09, ...,
7.35211074e-08, 7.93726684e-09, 2.32747843e-09],
[5.84857229e-09, 5.96697181e-09, 2.52968917e-08, ...,
4.54798699e-11, 1.39827705e-07, 8.80456333e-11],
[2.01175007e-10, 2.49047503e-08, 8.23493849e-07, ...,
1.22790955e-09, 2.94869028e-06, 2.74545178e-11],
...,
[7.61767455e-11, 4.67602177e-07, 2.13923772e-06, ...,
1.18145316e-09, 4.10481618e-07, 2.25870012e-09],
[9.49689719e-12, 3.34544097e-07, 1.10588144e-06, ...,
3.03792256e-12, 2.48198660e-07, 3.08238279e-09],
[1.88095033e-08, 1.15312124e-08, 9.96940974e-10, ...,
1.94757055e-09, 3.44197218e-07, 1.43695189e-09]], dtype=float32)}, 'layers_2': {'bias': Array([1.5663831e-07, 8.9502172e-10, 7.5773130e-08, 1.6520611e-11,
6.1840069e-08, 8.4190965e-08, 3.3300254e-09, 1.6127383e-06,
2.5834258e-06, 7.1017979e-07, 2.0463721e-08, 7.1273604e-10,
9.5492950e-08, 1.6264083e-06, 7.5558603e-08, 1.7720673e-06,
6.9113162e-07, 1.6176837e-05, 1.2764440e-06, 1.7619958e-07,
7.1275049e-06, 1.1940192e-10, 3.4136417e-07, 5.8799782e-07,
6.8879359e-07, 8.6367309e-06, 7.1705339e-09, 3.4837456e-07,
2.8584361e-06, 6.5155302e-07, 6.8991767e-08, 2.6852999e-06], dtype=float32), 'kernel': Array([[2.96564184e-12, 1.36221356e-09, 2.11616613e-10, ...,
4.31485847e-13, 3.82900850e-10, 0.00000000e+00],
[6.30433206e-10, 6.57027215e-08, 1.36275935e-09, ...,
1.89206204e-07, 9.88098492e-10, 1.03761943e-06],
[8.94471025e-11, 2.10637841e-09, 3.02733416e-09, ...,
1.59535407e-08, 2.00111305e-09, 1.41246559e-07],
...,
[8.19176649e-13, 5.16606369e-10, 4.66779150e-11, ...,
1.00258057e-11, 6.28301508e-11, 0.00000000e+00],
[1.53100554e-09, 1.18840280e-08, 4.72080375e-10, ...,
1.03644444e-08, 1.38739100e-08, 5.12688780e-09],
[4.83479867e-10, 5.43474812e-08, 1.26626265e-08, ...,
2.29386199e-08, 7.69664688e-09, 3.64309982e-09]], dtype=float32)}, 'layers_3': {'bias': Array([1.4600332e-04, 4.7886562e-07], dtype=float32), 'kernel': Array([[7.05537140e-09, 2.50457921e-09],
[2.65230113e-07, 1.00290754e-06],
[1.38171054e-05, 5.22845949e-06],
[4.94151053e-10, 3.29913596e-10],
[5.28803241e-07, 4.98256414e-09],
[6.28160592e-07, 5.94850462e-08],
[2.41464466e-08, 5.75823300e-09],
[3.59914588e-06, 5.77254355e-07],
[2.47661810e-05, 2.49395248e-06],
[5.36162474e-08, 6.74248071e-08],
[6.24525820e-10, 1.22454080e-09],
[1.27230601e-06, 3.22332795e-07],
[2.25950529e-08, 6.60549171e-09],
[1.08615620e-06, 4.52171236e-07],
[1.19022248e-09, 8.73647821e-09],
[5.72527767e-08, 3.07830675e-07],
[3.36002840e-12, 6.62720057e-09],
[2.29805701e-05, 7.49882292e-06],
[9.07674913e-09, 2.26814655e-06],
[6.19271390e-08, 3.97951050e-09],
[9.09209666e-06, 6.86775792e-08],
[5.61322655e-10, 2.17616619e-11],
[6.06593005e-07, 2.22726769e-07],
[1.28781294e-05, 8.50531421e-07],
[8.11005094e-08, 7.44685281e-07],
[1.78665832e-05, 6.14490546e-06],
[9.81877406e-07, 6.15124065e-07],
[3.25505489e-08, 9.20100476e-08],
[4.83703934e-06, 9.71273693e-08],
[1.64454887e-05, 4.98379904e-06],
[1.37951135e-08, 2.54435939e-08],
[3.63278900e-08, 9.68863656e-09]], dtype=float32)}}}),
EmptyState()),
Array(0.26343495, dtype=float32))We repeat the training_step K times with the following function (each training step is called an epoch).
def train_me(K, key, theta_0, opt_state):
theta = theta_0
key, key_ = jax.random.split(key)
vals = []
for k in tqdm(range(K)):
theta, opt_state, val = train_step(theta, opt_state, key)
vals.append(float(val))
key, key_ = jax.random.split(key)
return vals, theta# with writer.as_default():
key0 = jax.random.key(43)
results, theta = train_me(50000, key0, theta_0, opt_state)100%|██████████| 50000/50000 [01:01<00:00, 814.70it/s]On a modern cpu, optimization should be done within few minutes. It would be dramatically faster on hardware adapted to deep-learning. To see how the training has performed, we can plot the empirical errors against the number of epochs.
plt.plot(np.sqrt( results) )
plt.xscale('log')
plt.yscale('log')
plt.grid()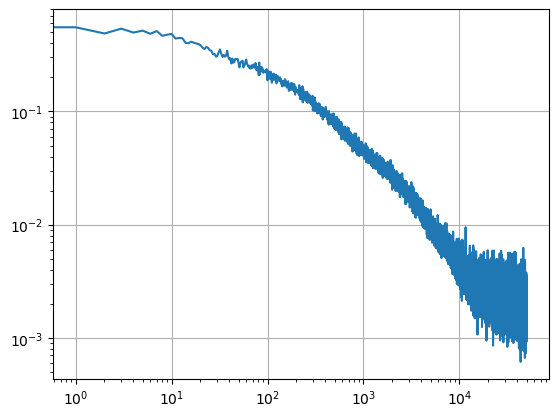
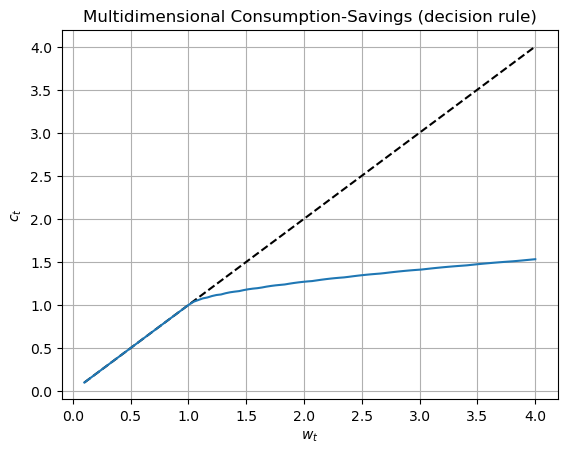
In the training graph, one can see that errors are decreasing until they reach \(2*10^{-3}\) on average (the errors are volatile both because they depend on a specific random draw and because only two such random draws are used to approximate the expectation function). The numbers in the graph represent the mean of the squared residuals. We show the constructed decision rule below.
wvec = np.linspace(wmin, wmax, 100)
ζvec, hvec = dr(theta, wvec*0, wvec*0, wvec*0, wvec*0, wvec)
plt.title("Multidimensional Consumption-Savings (decision rule)")
plt.plot(wvec, wvec, linestyle='--', color='black')
plt.plot(wvec, wvec*ζvec)
plt.xlabel("$w_t$")
plt.ylabel("$c_t$")
plt.grid()