Discretization
What’s wrong with Monte-Carlo Simulations?
Define \(X(\epsilon) = U(C(\epsilon))\) where \(U(c)=\frac{c^{1-\gamma}}{1-\gamma}\) and \(C(\epsilon) = e^{\epsilon}\). We want to compute \(E_{\epsilon} X(\epsilon)\) precisely.
How many draws do we need ?
![Monte Carlo estimate of E[X] versus number of draws in a 2x1 layout with empty second panel.](mc_estimates_layout.png)
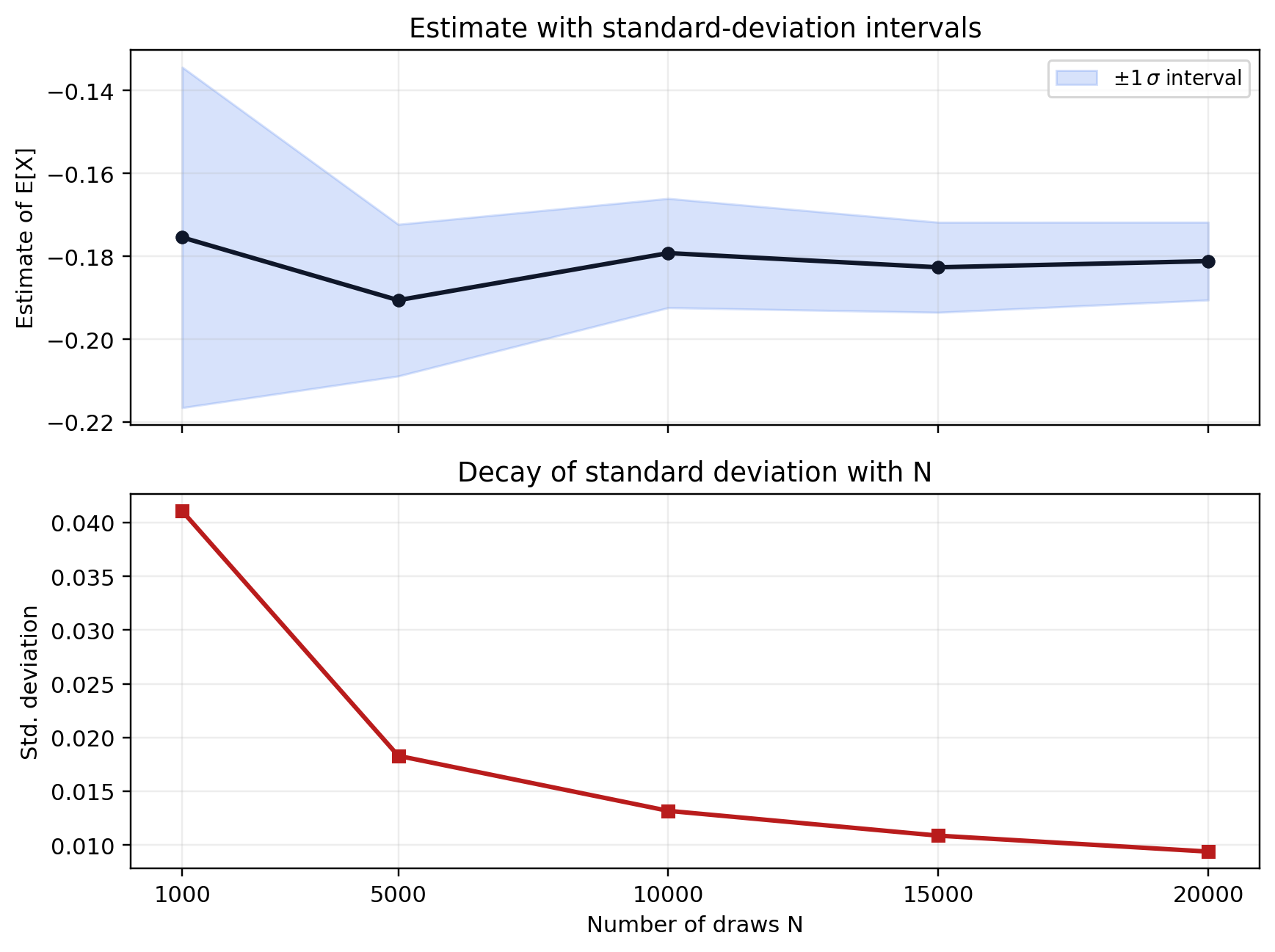
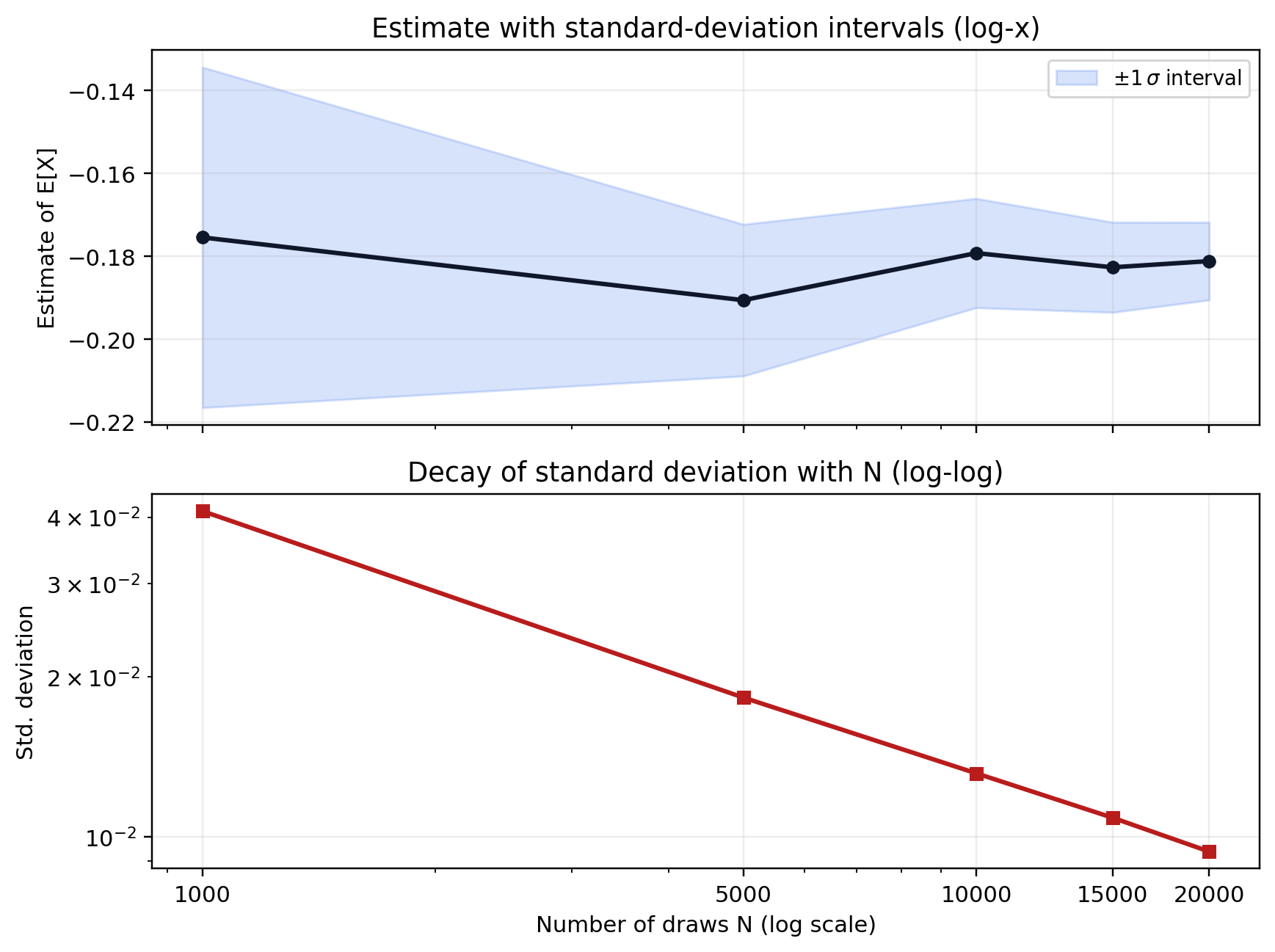
The decrease in standard deviations is too slow.
Define the Model in Julia
Monte-Carlo estimates for various N:
Monte-Carlo estimates of the variance for various N:
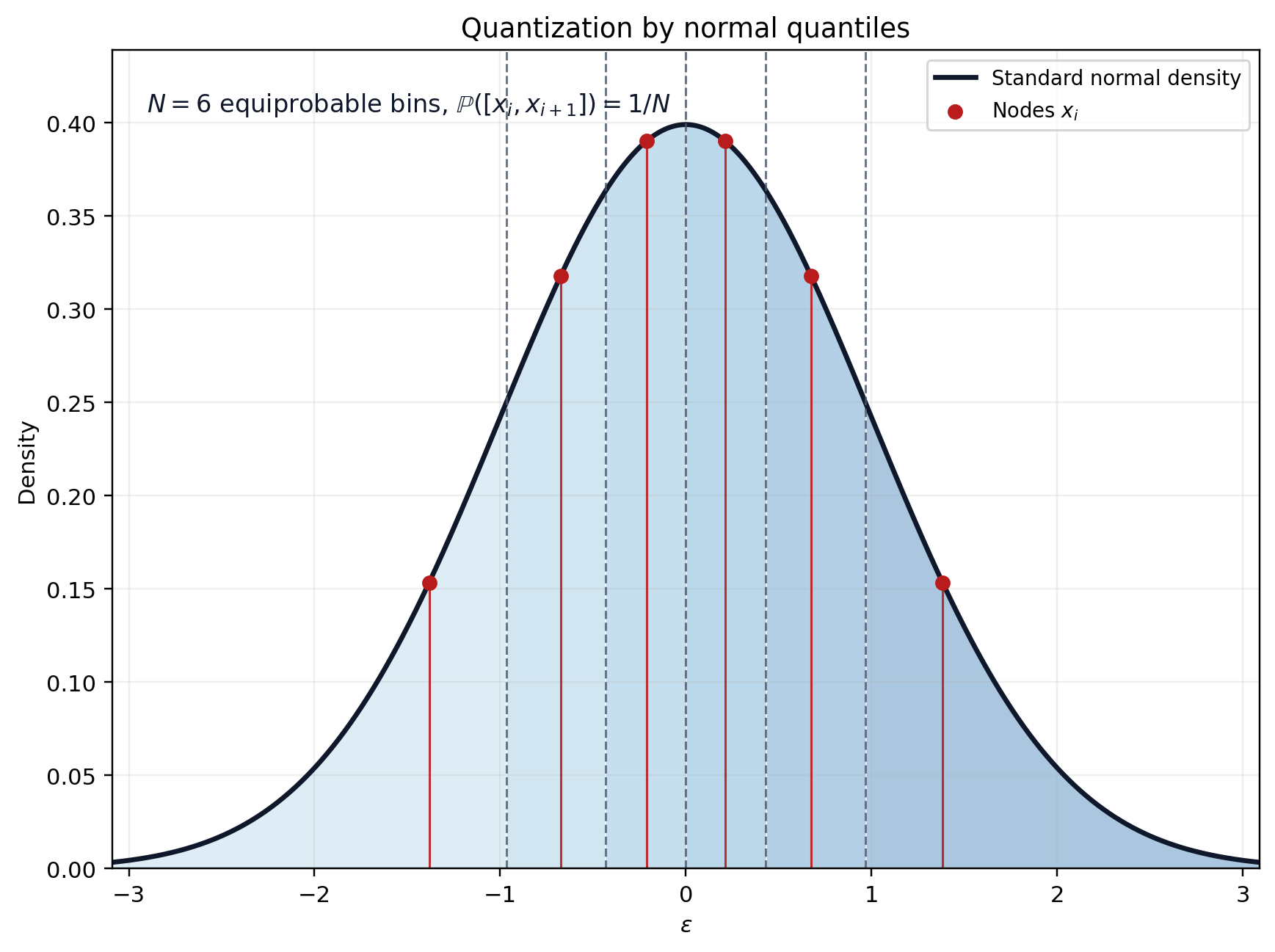
Quantization using quantiles
Equiprobable discretization
- Works for any distribution with pdf \(\mu\) and cdf \(\mu\)
Split the space into \(N\) equiprobable quantiles: \[(I_i=[a_i,a_{i+1}])_{i=1:N}\] such that \(\mathbb{P}(\epsilon \in I_i)=\frac{1}{N}\)
This yields: \(a_1=-\infty, a_{N+1}=\infty, a_i = \xi^{-1}\left(\frac{i-1}{N}\right)\)
Choose the nodes as the median of each interval: \[\mathbb{P}(\epsilon\in[a_i,x_i]) = \mathbb{P}(\epsilon\in[x_i,a_{i+1}])\] This yields: \(\boxed{x_i = \xi^{-1}\left(\frac{i-0.5}{N}\right)}\)
The quantization is simply \((w_i, x_i)_{i=1:N}\) with \(w_i = 1/N\).
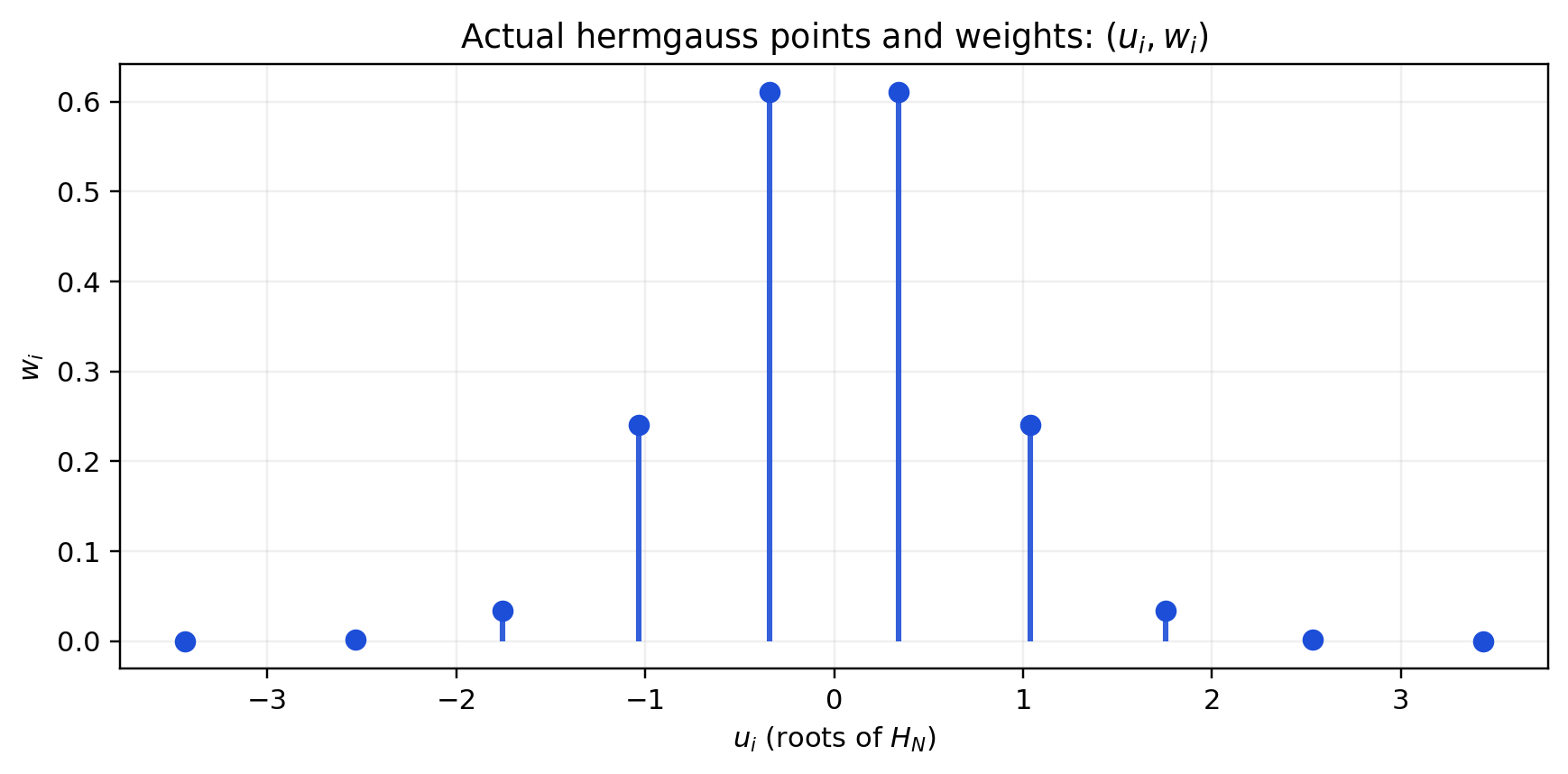
Gauss-Hermite
- Very accurate if a function can be approximated by polynomials
- Bad:
- imprecise if function \(f\) has kinks or non local behaviour
- points \(\epsilon_n\) can be very far from the origin (see below)
- not super easy to compute weights and nodes (but there are good libraries)
- imprecise if function \(f\) has kinks or non local behaviour