i.e. train the nets \(\varphi^D\) and \(\varphi^E\) to predict the “data from the data”? (it is called autoencoding)
Encoders / Decoders (2/2)
The relation \(\varphi^D( \varphi^E(x_n; \theta^E), \theta^D) ~ x_n\) can be rewritten as
\[x_n \xrightarrow{\varphi^E(; \theta^E)} h \xrightarrow{\varphi^D(; \theta^D)} x_n \]
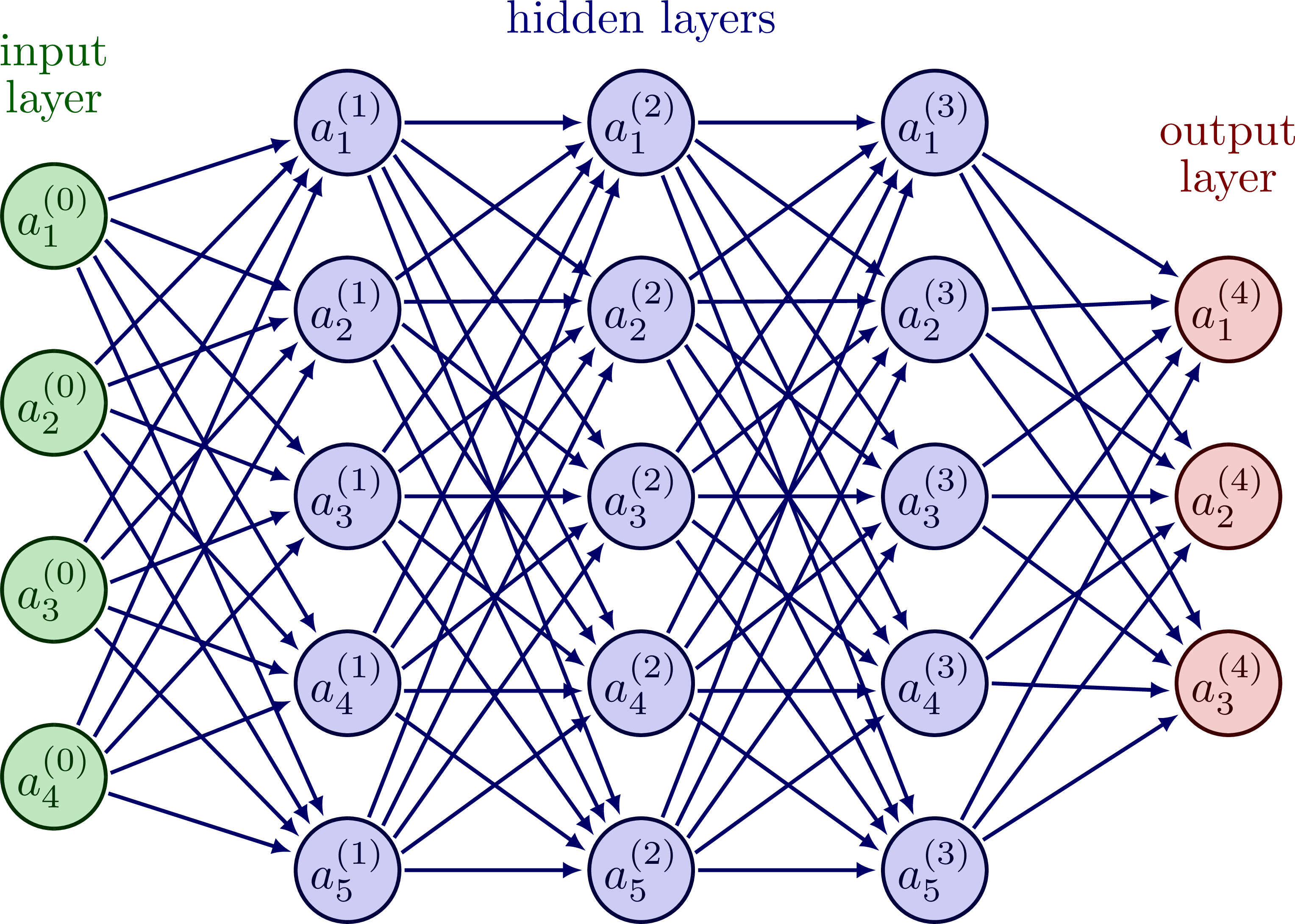
When that relation is (mostly) satisfied and \(\mathbb{R}^h << \mathbb{R}^x\), \(h\) can be viewed as a lower dimension representation of \(x\). It encodes the information as a lower dimension vector \(h\) and is called learned embeddings.
instead of \(\underbrace{x_n}_{\text{prompt}} \rightarrow \underbrace{y_n}_{\text{text completion}}\)
one can learn \(\underbrace{h_n}_{\text{prompt (low dim)}} \xrightarrow{\varphi^C( ; \theta^C)} \underbrace{h_n^c}_{\text{text completion (low dim)}}\)
it is easier to learn
and perform the original task as \[\underbrace{x_n}_{\text{prompt}} \xrightarrow{\varphi^E} h_n \xrightarrow{\varphi^C} h_n^C \xrightarrow{\varphi^D} \underbrace{y_n}_{\text{text completion}}\]
This very powerful approach can be applied to combine encoders/decoders from different contexts (ex Dall-E)
Attention
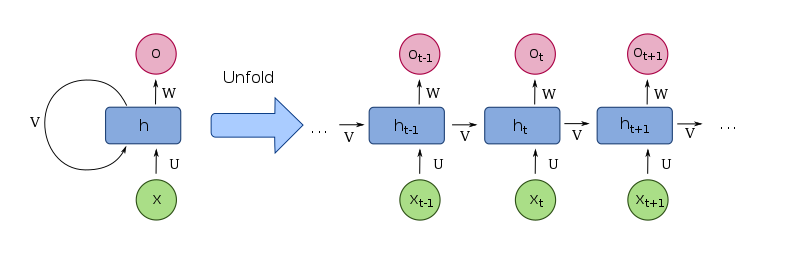
Main flaw with the recursive approach:
the context made to predict new words/embeddings puts a lower weight on further words/embeddings
this is related to the so-called vanishing gradient problem
With the attention mechanism, each predicted word/embedding is determined by all preceding words/embeddings, with different weights that are endogenous.