Text Analysis
Data-Based Economics, ESCP, 2025-2026
2026-02-11
What can we do?
How to deal with text?
- Recall: big data contains heterogenous data
- text / images / sound
Example 1: FOMC meetings
Taking the Fed at its Word: A New Approach to Estimating Central Bank Objectives using Text Analysis by Adam H. Shapiro and Daniel J. Wilson link
- Remember the Taylor rule? We tried to estimate it from the data.
- Generalized version: \(i_t = \alpha_\pi (\pi_t-\pi^{\star}) + \alpha_y (y_t-y)\)
- Is there a way to measure the preferences of the central bank? (coefficients and inflation target?)
- Shapiro and Wilson: let’s look at the FOMC meeting transcripts
- Excerpts (there are tons of them: 704,499)
I had several conversations at Jackson Hole with Wall Street economists and journalists, and they said, quite frankly, that they really do not believe that our effective inflation target is 1 to 2 percent. They believe we have morphed into 1+1/2 to 2+1/2 percent, and no one thought that we were really going to do anything over time to bring it down to 1 to 2.
Sep 2006 St. Louis Federal Reserve President William Poole
Like most of you, I am not at all alarmist about inflation. I think the worst that is likely to happen would be 20 or 30 basis points over the next year. But even that amount is a little disconcerting for me. I think it is very important for us to maintain our credibility on inflation and it would be somewhat expensive to bring that additional inflation back down.
March 2006 Chairman Ben Bernanke
With inflation remaining at such rates, we could begin to lose credibility if markets mistakenly inferred that our comfort zone had drifted higher. When we stop raising rates, we ought to be reasonably confident that policy is restrictive enough to bring inflation back toward the center of our comfort zone, which I believe is 1+1/2 percent…So for today, we should move forward with an increase of 25 basis points…
Jan 2006 Chicago Federal Reserve President Michael Moskow
We are determined to ensure that inflation returns to our two per cent medium-term target in a timely manner. Based on our current assessment, we consider that the key ECB interest rates are at levels that, maintained for a sufficiently long duration, will make a substantial contribution to this goal. Our future decisions will ensure that our policy rates will be set at sufficiently restrictive levels for as long as necessary.
Mar 2024 Press conference from Christine Lagarde
Example 2
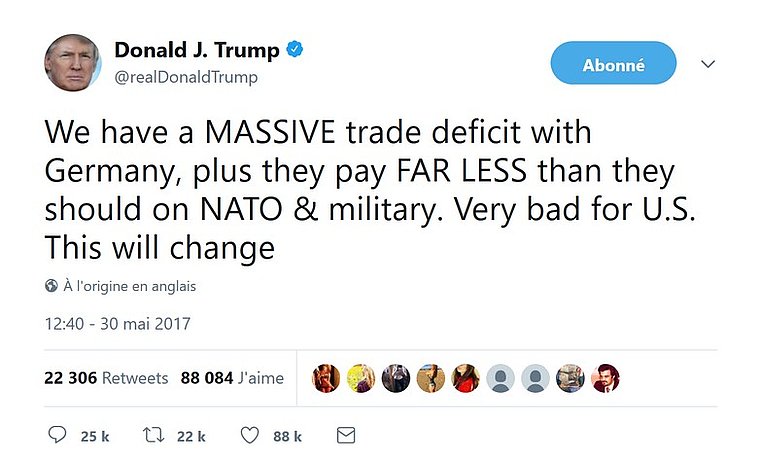
- Suppose you work in the trading floor of a financial instutition
- These kind of tweets have disturbing impact on the markets. You need to react quickly.
- You need a machine to assess the risk in real time.
- More generally, twitter (X) is a quite unique source of real-time data
- How do you analyse the content of the tweets?
- Comment: actually it’s not only the content of the tweets, but who reads, who retweets: graph analysis
Text-mining: what can we extract from texts?
The traditional branches of text analysis1 are:
- sentiment analysis
- associate positivity/negativity to a text
- precise meaning of “sentiment” is context dependent
- topic modeling
- classify texts as belonging to known categories (supervised)
- finding likely texts (unsupervised)
- named-entity recognition
- find who gets mentioned in the text
- example: A Cross-verified Database of Notable People, 3500BC-2018AD
- event-extraction
- recognize mention of events
Natural Language Processing

Natural Language Processing is a subfield of machine learning.
- it consists in quantifying information used in a text…
- by using many text analysis techniques (stemming, tokenization, …)
- … so that it can be incorporated in machine learning analysis
The even-less glamorous part
Before getting started with text analysis, one needs to get hold of the text in the first place
- how to extract
- webscraping: automate a bot to visit website and download text
- document extraction: for instance extract the text from pdf docs, get rid of everything irrelevant
- how to store it?
- what kind of database? (sql, mongodb, …)
- this can require some thought when the database is big
Extracting features
Extracting features
Before any statistical analysis can be applied, the text needs to be preprocessed.
- Goal is to transform the text into a numerical vector of features
- Stupid approach: “abc”->[1,2,3]. Very inefficient.
- we need to capture some form of language structure
- All the steps can be done fairly easily with nltk …
- nltk is comparable to sklearn in terms of widespread adoption
- … or with sklearn
Processing steps
We will review the following processing steps:
- tokenization
- stopwords
- lexicon normalization
- stemming
- lemmatization
- POS tagging
Tokenization
Split input into atomic elements.
- We can recognize:
- sentences
- words
from nltk.tokenize import sent_tokenize
txt = """Animal Farm is a short novel by George Orwell. It was
written during World War II and published in 1945. It is about
a group of farm animals who rebel against their farmer. They
hope to create a place where the animals can be equal, free,
and happy."""
sentences = sent_tokenize(txt)
print(sentences)Part-of speech tagging
- Sometimes we need information about the kind of tokens that we have
- We can perform part-of-speech tagging (aka grammatical tagging)
-
This is useful to refine interpretation of some words
- “it’s not a beautiful thing”
- vs “it’s a beautiful thing”
- connotation of beautiful changes
Simplifying the text (1): stopwords
- Some words are very frequent and carry no useful meaning
- They are called stopwords
- We typically remove them from our word list
Simplifying the text (2): lexicon normalization
- Sometimes, there are several variants of a given word
- tight, tightening, tighten
- Stemming: keeping the word root
-
Lemmatization: keeps the word base
- linguistically correct contrary to stemming
Sentiment analysis
Sentiment analysis
- What do we do now that we have reduced a text to a series of word occurrences?
- Two main approaches:
- lexical analysis
- machine learning
Lexical analysis
- Use a “sentiment dictionary” to provide a value (positive or negative) for each word
- sum the weights to get positive or negative sentiment
- Example: \[\underbrace{\text{Sadly}}_{-}\text{, there wasn't a glimpse of }\underbrace{\text{light}}_{+} \text{ in his } \text{world } \text{ of intense }\underbrace{\text{suffering.}}_{-}\]
- Total:
- -1+1-1. Sentiment is negative.
Problems:?
- doesn’t capture irony
- here, taking grammar into account would change everything
- our dictionary doesn’t have weights for what matters to us
\[ \text{the central bank forecasts increased }\underbrace{\text{inflation}}_{?}\]
Learning the weights
Idea: we would like the weights to be endogenously determined \[ \underbrace{\text{the}}_{x_1} \underbrace{\text{ central}}_{x_2} \underbrace{\text{ bank}}_{x_3} \underbrace{\text{ forecasts}}_{x_4} \underbrace{\text{ increased} }_{x_5} \underbrace{\text{ inflation}}_{x_6}\]
- Suppose we had several texts: we can generate features by counting words in each of them (absolute frequencies)
| the | central | bank | forecasts | increased | inflation | economy | exchange rate | crisis | sentiment | |
|---|---|---|---|---|---|---|---|---|---|---|
| text1 | 1 | 1 | 2 | 1 | 1 | 2 | -1 | |||
| text2 | 3 | 1 | 1 | 2 | +1 | |||||
| text3 | 4 | 1 | 1 | 1 | 1 | -1 | ||||
- We can the train the model: \(y = x_1 w_1 + \cdots x_K w_K\) where \(y\) is the sentiment and \(w_i\) is wordcount of word \(w_i\)
- of course, we need a similar procedure as before (split the training set and evaluation set, …)
- we can use any model (like naive bayesian updating)
- This approach is called Bag of Words (BOW)
Improving the “Bag of Words” approach
Bag of words approach with raw word count has a few issues:
- it requires a big training set with labels
- it overweights long documents
- there is noise due to the very frequent words that don’t affect sentiment
Improvement: TF-IDF (Term-Frequency*Inverse-Distribution-Frequency)
- replace word frequency \(w\) by \[\text{tf-idf} = w\frac{\text{number of documents}}{\text{number of documents containing $w$}}\]
- reduces noise due to frequent words
Conclusion
Recent trends for text analysis:
- deep learning
- very flexible model
- replace tokenization by abstract embedding space
- generative AI
- can perform many text analysis text without pretraining!
Next week
Introduction to Large Language Models